Retail Demand Forecasting Transformation with o9 & Azure
A top US beverage brand slashed manual work by 70% and boosted forecast accuracy by 20% by unifying fragmented pipelines into an o9 and Azure-powered forecasting solution.
The Client
A leading US-based beverage chain with over 30,000 locations globally.
The Challenge
The client, a leading US-based global beverage provider, faced significant challenges with their retail demand forecasting capabilities. As one of the most recognizable brands worldwide, known for premium beverages and unique in-store experiences, the company needed to align its data infrastructure with its market position.
The existing architecture consisted of fragmented and manually intensive data pipelines involving multiple systems, like Oracle EBS, Product Information Management (PIM), and Apache NiFi. As data volumes grew, this legacy setup revealed several critical limitations:
- Lack of scalability to accommodate growing data processing needs
- Insufficient reliability for business-critical analytics
- Absence of real-time capabilities required for timely decision-making
- Data silos preventing cross-functional collaboration
- Inconsistent data quality undermining trust in forecasting outputs
- Limited in-house expertise with modern data solutions
The company recognized the need to consolidate independent forecasting approaches from different departments under a unified internal initiative. This required a significant investment in improving their demand forecasting capabilities.
Key objectives included:
- Creating a cross-functional approach to drive more informed demand signals
- Designing capabilities that integrate tools to create a single forecast for organizational decision-making
- Implementing solutions that enable agile what-if scenarios to support leadership decisions
Share this Document
The Solution
GSPANN implemented a transformational approach to demand planning, focusing on improving forecast quality through an enterprise-wide, integrative design with new technology and processes. Our objective was to boost the company’s success by introducing advanced retail demand forecasting techniques.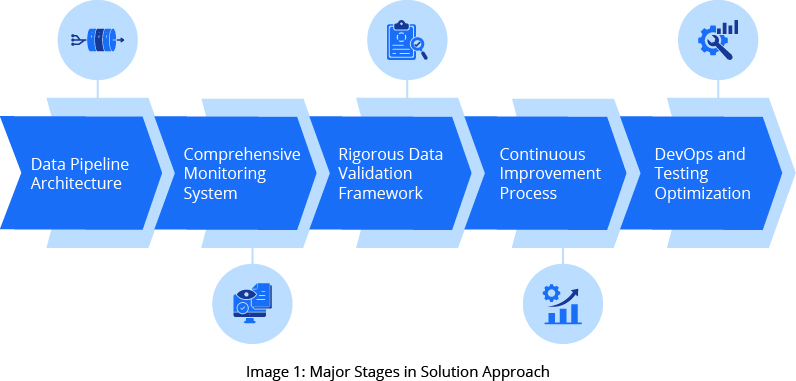
Our solution comprised several key stages, summarized in Image 1, including:
Automating Data Pipeline Architecture
- Designed and built automated data pipelines that process both batch and real-time streaming data
- Handled diverse data sources, including NiFi, flat files, and APIs (DPI)
- Ensured high-quality data ingestion, cleansing, and transformation for downstream analysis
Building a Comprehensive Monitoring System
- Utilized Databricks to monitor cluster performance, jobs, and data processing activities
- Implemented NiFi for robust monitoring of data flow through ingestion stages
- Developed Databricks dashboards for the proactive identification of abnormalities in data loads
Implementing a Rigorous Data Validation Framework
- Created thorough data comparison mechanisms between source and target systems
- Implemented row count validations to ensure data integrity
- Developed an automated validation framework using Python and SQL
- Set up automated checks after each batch job with email/Slack alerts for discrepancies
Establishing a Continuous Improvement Process
- Established methodology for analyzing, designing, and deploying enhancements
- Aligned technical solutions with business requirements and architecture
- Implemented changes through feature development, bug fixes, and performance optimizations
- Deployed enhancements following best practices to minimize operational disruption
Performing DevOps and Testing Optimization
- Created deployment scripts using Jenkins for CI/CD of Databricks objects and workflows
- Implemented Pytest notebooks to validate test cases for every code change
- Established reusable components for future projects
Business Impact
The implementation of the modernized data architecture and o9 solutions delivered significant measurable improvements:
Enhanced Data Integration and Visibility
- Consolidated data from previously isolated sources (Oracle, NiFi, external systems)
- Transformed limited weekly snapshots into near real-time, end-to-end data flows
- Provided access to a full year of historical data with daily-level drill-down capabilities
- Enabled stakeholders to monitor trends and identify issues proactively
Quantifiable Performance Improvements
- Improved data accuracy by 15-20% through automated validation and cleaner transformation pipelines
- Reduced manual intervention in data workflows by over 70%, decreasing errors and freeing resources
- Successfully implemented and maintained 36 data pipelines across Databricks and NiFi
- Increased daily data processing capacity from under 10 GB to over 200 GB
Operational Efficiency Gains
- Reduced integration time for new data sources from several weeks to just a few days
- Supported automated reporting across multiple business units
- Decreased reliance on email-based data exchanges
- Enabled more structured, data-driven discussions with partners and internal teams
Business Capability Enhancements
- Improved planning capabilities, accuracy, and efficiency
- Integrated external forecasts with increased visibility across the enterprise
- Enhanced quality of engagement with cross-functional teams and suppliers
- Consistently delivered quality data to the o9 application within SLAs
Technologies Used
Related Capabilities
Transforming raw data into reliable insights for strategic decisions.
Our data engineering services create accessible, reliable pipelines through integration, transformation, and automation while optimizing storage architecture for scalability. These capabilities reduce silos and costs while enhancing data quality and accessibility, ultimately supporting data-driven decision-making with unified views across systems for improved operational efficiency and strategic planning.



