
About the Client
A food and beverage company with an extensive chain of stores worldwide.
The Challenge
The company used an IBM AS-400 with a DB2 Database for its revenue accounting system. After each fiscal period closure, the company was required to summarize and send accounting data to the General Ledger but faced data accuracy problems. One of the major challenges they encountered was that the data originated from different upstream systems. Their current data governance implementation had difficulty resolving conflicts between inputs.
The company also needed help applying business rules to produce valid data intended for its users and stakeholders. They wanted user-friendly reports for their day-to-day activities, which proved impossible on the old system due to its underlying technology stack.
An additional challenge was that the company needed to validate a massive amount of data, with daily data items numbering in the millions. The company sought a solution to guarantee the integrity of its data pipeline after data conversion and business rules were applied. They needed a scalable legacy system modernization solution to:
- Verify each row of every data record.
- Verify that each business rule is applied correctly.
- Verify there are no data discrepancies, including duplicates and null entries.
In short, the company needed:
- Accurately ingested financial data: The company was looking for a solution capable of accurately ingesting accounting data from different sources.
- User-friendly reports: The company sought a system that could apply business rules correctly and guard against discrepancies to produce easily readable reports.
- Validation of vast amounts of data: Performing manual validation was challenging due to the high volume of transactions received, totaling more than 8 million daily transactions.
Our Solution
Our team designed and executed a migration plan that moved ten years of historical data along with the latest daily feeds from different upstream systems to an Azure data lake. We configured and scheduled extract, transform, and load (ETL) jobs to summarize data and send reports to business users through Power BI and Azure SQL Reporting.
Our quality engineering team assisted the company in the validation performed during data migration and conversion. We also performed business validation on revenue accounting system data. The team validated business rules applied to the data and conducted data sampling testing for migrated and converted records in Azure Databricks via Structured Query Language (SQL). Using SQL in our solution was ideal because, at this stage, there was no UI (User Interface) or API involvement.
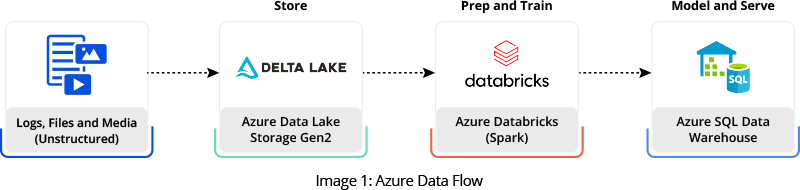
Image Credit: Tutorial: Extract, transform, and load data by using Azure Databricks
During our preliminary analysis, we explored and proposed two proof-of-concepts. One used ‘Great Expectations,’ and the other leveraged ‘Tricentis Tosca Data Integrity’ (Tosca DI).
Great Expectations is an open-source Python library that helps produce assertions for PySpark data frames. This would have been a good choice as we built our software on Azure Data Lake. However, subsequent investigation uncovered some shortcomings.
Tosca DI successfully fulfilled all our automation needs, enabling us to compare a high volume of data on an enormous scale in a reasonable timeframe. The company was already utilizing Tosca for other applications. Consequently, the company decided upon Tosca and we recommended the Tosca DI module, a tool purposefully designed to meet data integrity testing needs.
Our team developed automation scripts using SQL in Tosca DI to address the challenges we encountered. These scripts effectively identified numerous functional defects that functional testing had previously missed due to the overwhelming data scale. These automation scripts became indispensable in regression testing, which was manually impractical due to the data volume.
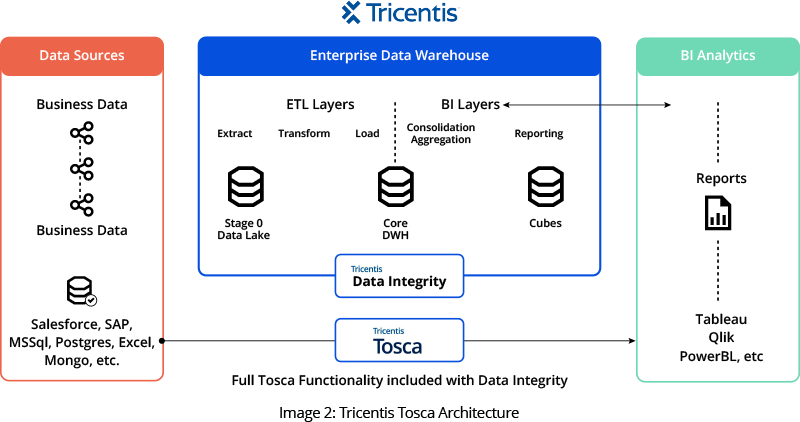
Image Credit: Tricentis Tosca
Below are some key results our legacy system modernization solution achieved through automation:
- Metadata testing: This allows the company to obtain information about the data within the schema, for example, the column names, the data type of a column, and constraints imposed on the data. The new system incorporates a rich set of additional validation that includes checks on the data type, length, constraint, and naming conventions.
- Data completeness testing: All expected data is extracted from the source and loaded into the target without loss or corruption. The company can confirm the row count, aggregate column data values, validate primary keys, and perform a full-value comparison validation. In addition, they can now monitor missing setups.
- Data quality testing: The new system allows us to check that the business rules and logic have been applied to the ETL pipeline. Quality tests detect duplicate data, confirm that business rules have been applied, and perform data integrity validation.
- Draft run: Our solution lets the company view journal data before the final posting to the company’s Oracle accounting systems.
- Fully automated auto-accept process:The new system validates all the daily store data per business requirements.
- Scalability and futureproofing:Testing and validation automation using Tosca DI helped validate millions of upstream records in minutes.
Business Impact
One of the greatest benefits company stakeholders experienced was moving away from traditional AS-400 “green screen” text-based apps into a modern graphical user interface (GUI).
The other areas of business impact include:
- Greatly enhanced and user-friendly interfaces improve daily work: The new intuitive navigation capabilities have reduced business team onboarding times. The day-to-day processing is now faster and easier due to the enhanced sales estimate maintenance screens. The new UI dashboards also provide advanced reporting and analytics.
- Increased revenue accuracy: The new system increased revenue accuracy by up to $200,000 monthly. Also, the store comp process has been dramatically streamlined and shows increased reporting accuracy.
- Improved sales estimating: Due to the ready availability of accurate data, the new system improved the company’s ability to estimate sales. This substantially impacted its offline sales discount process and has benefited the company overall. The new system of alerts and notifications provides improved visualization for trending vs average sales.
- Hard close time reduced by 95%: The hard close processing and validation completion now takes only 2 hours. Under the old system, this took up to 2 days to complete.
Related Capabilities
Utilize Actionable Insights from Multiple Data Hubs to Gain More Customers and Boost Sales
Unlock the power of the data insights buried deep within your diverse systems across the organization. We empower businesses to effectively collect, beautifully visualize, critically analyze, and intelligently interpret data to support organizational goals. Our team ensures good returns on the big data technology investments with the effective use of the latest data and analytics tools.
Related Services
Technologies Used
- Node.js
- React.js
- MongoDB Cosmo
- Express.js
- Apache NiFi
- Microsoft Azure Databricks
- Oracle EBs
- Tricentis Tosca DI





