
Why Snowflake?
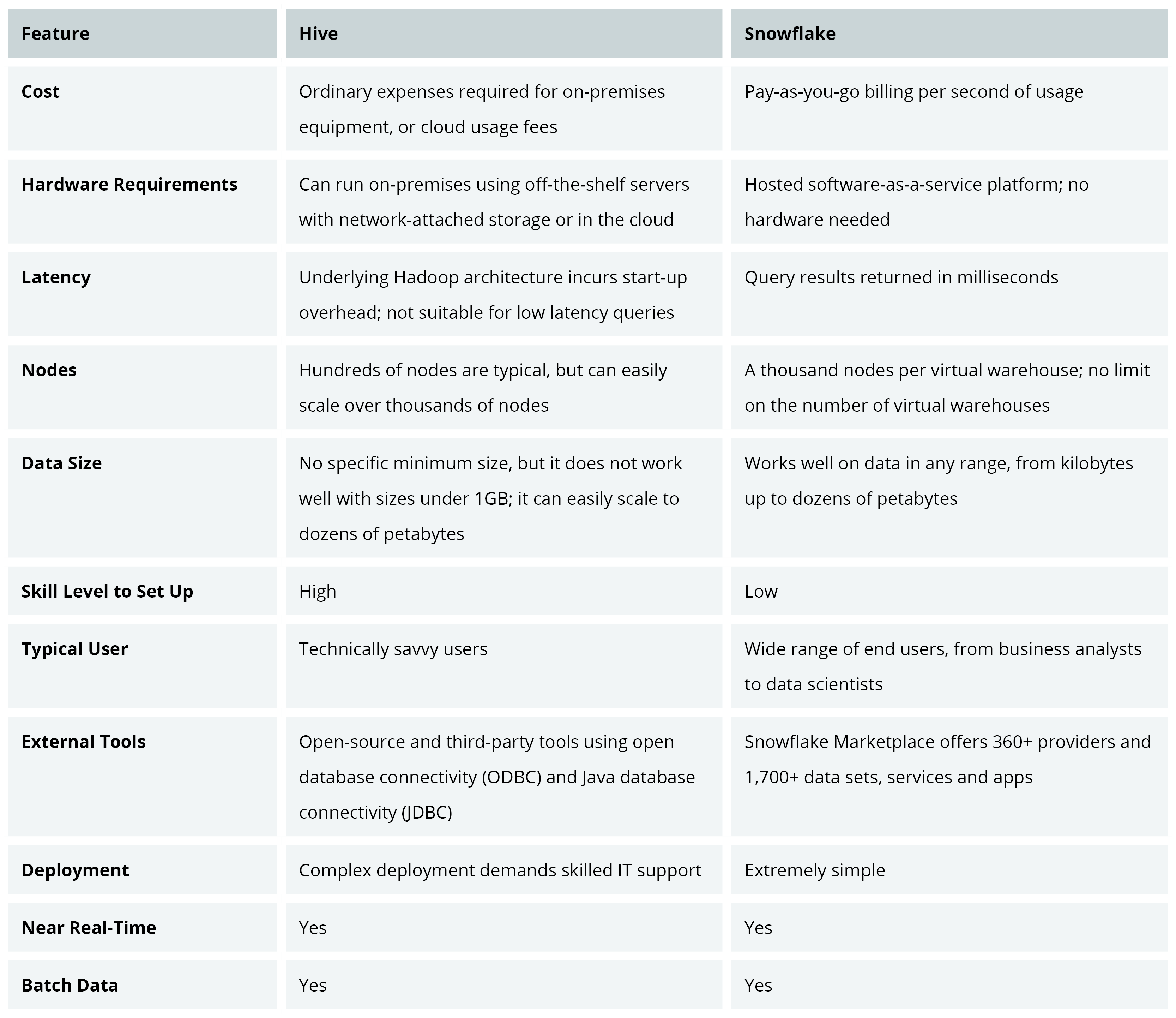
Snowflake is the best option for data warehousing needs. It offers individual virtual warehouses and excellent service for real-time statistical analysis. Snowflake is perfect when you wish to compute capabilities to handle workloads autonomously. Its skill level requirements are extremely low, deployment is simple, and overhead management costs are almost non-existent.
Snowflake stands out as one of the top data warehouses due to its high performance, query optimization, and low latency queries, enabled by virtual warehouses. Its architecture allows storage and computes services to scale independently so that customers can use and pay for storage and computation separately.
Another attractive feature of Snowflake is its respectable list of partners in various areas, including integration, data science, AI/ML, and business intelligence tools. It is also well known for its industry sector partners representing the financial, technology, retail, healthcare, media, and entertainment industries.
Why Apache Hive?
Apache Hive is an open-source data warehouse platform that manages large, distributed data sets. Hive was formerly a Hadoop sub-project, which has now “graduated” to a full-fledged project in its own right. It supports standard SQL queries and enables extract/transform/load (ETL) tasks, reporting, and data analysis. Hive supports data partitioning at the table level (sharding), which can significantly improve performance and scalability. Meta store or Metadata store is a big plus in the architecture, which makes the lookup easy. Hive supports file formats such as textile, Sequence File, ORC, RCFile, Avro Files, Parquet, LZO Compression, etc.
Hive has plenty of support on most major cloud platforms, like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure. From a business perspective, what is of potential interest is that it can also run on-premises using inexpensive off-the-shelf servers and directly attached storage arrays. This means you can handle massive amounts of data without worrying about cloud storage and usage costs. Hive can also easily integrate with other Apache Software Foundation projects, including Airflow, Spark, MapReduce, and Slider.
The underlying data layer, Hadoop, can easily handle hundreds of terabytes of data and can scale to dozens of petabytes. However, Hadoop has a big disadvantage: a noticeable start-up overhead, which makes it a poor choice for low-latency queries.
Comparing Snowflake and Apache Hive
While both technologies are commonly used for data warehousing and analytics, they have some key differences. Snowflake is a fully managed cloud platform, while Apache Hive is an open-source tool that runs on top of a Hadoop cluster. Snowflake uses a proprietary language called SQL, while Apache Hive uses an SQL-like language called HiveQL. Snowflake is designed to be highly scalable and flexible, while Apache Hive is more focused on data processing and analysis.
Benefits of Integrating Snowflake with Hive
Snowflake and Hive each have their strong points. However, if you combine the two technologies, you end up with a best-of-breed data warehouse platform. Snowflake tables act as a reference for the Hive tables. Querying in Snowflake is faster than Hive, as Snowflake has its own proprietary query engine. They have separate storage from computational services and get optimized performance at different layers.
You can accomplish data pipeline ETL by integrating Apache Spark with Hive. SparkSQL can share a metadata catalog with Hive, allowing you to create one-time-use table definitions. It makes it simpler to manage your schema in Hive while querying it from Snowflake. You can also achieve automation by connecting Spark or Hive to Apache Airflow. Airflow brings scheduling and monitoring into the picture.
Need help integrating Snowflake and Hive? Register here (form) to get a step-by-step code-level Snowflake and Hive integration guidance.
For the integration to work smoothly, the Apache Hive Metastore must be integrated with cloud storage on a platform such as AWS, GCP, or Azure. The Snowflake website has excellent documentation on how to use the Hive Metastore connector (https://docs.snowflake.com/en/user-guide/tables-external-hive.html).
Combining Snowflake and Apache Hive can provide following additional benefits:
- Improved performance and reliability
- Enhanced data analysis and insights
- Greater scalability and flexibility
- Easy and efficient SQL querying and analysis
- Powerful data processing capabilities
- Fully managed cloud platform
- Open-source, customizable architecture
- Ability to build highly-performant, data-driven applications and services
Real-World Examples of Snowflake and Apache Hive in Action
One example where Snowflake and Hive were successfully combined with other tools is documented in our case study, “Ace Your Inventory KPIs with Cloud-based Automation, o9, and BEAT”. In this case study, our Information Analytics team developed application layers that integrated purchase order, delivery, and sales order data to produce consolidated inventory transfer and sales information for one company. Technologies used to develop the application layers included PySpark, Databricks, Snowflake, and Hive.
In another case, a company struggled with data issues stemming from format mismatches, unavailability of specific data components, and other issues that resulted in poor data quality. They could not utilize the massive amount of data in systems across the enterprise to drive critical business decisions. Using Hive as a key component, our engineers implemented a data quality framework that helped identify errors during the data pipeline ETL process and rectify them during audits.
Snowflake was instrumental in resolving a problem documented in the case study, “A Unified Platform Provides Cross-Channel Information to Your Business Partners”. It showcases the company that had hundreds of partners and physical representation in thousands of outlets worldwide. The lack of comprehensive product management severely impacted their online-to-offline customer journeys. Using Snowflake, among other technologies, our Content team built a comprehensive and unified data source ingestion mechanism to open full market potential. With the new system, digital, retail, and wholesale customers can access the same catalog of products, opening previously unavailable marketing channels for the company.
Conclusion
Both Apache Hive and Snowflake are excellent data warehouse platforms. Each has its advantages and disadvantages. When combined, they offer a powerful best-of-breed data warehouse platform. Hive gives you superior data handling and massive storage. Snowflake gives you lightning-fast queries and integration with advanced AI/ML-driven data analytics dashboards. This integration provides a low-cost and scalable platform that promises to move your business to the next level.





