Most enterprise data engineering teams are spending a disproportionate amount of time reacting to production incidents. It is not that the monitoring tools are bad. The problem is that the model for responding to those incidents has not kept pace with the scale and complexity of modern data platforms running on Databricks, Snowflake, and multi-cloud infrastructure.
The average organization receives close to 3,000 data and operational alerts every day. Around 63% of those go unaddressed. Engineering toil rose 30% in 2025, the first increase in five years, and 73% of organizations have experienced outages directly tied to alerts that were seen but left unattended. These are not edge cases. They are the baseline for how most enterprise data teams operate today.
The instinctive response is to add more runbooks, tighten on-call schedules, or layer on another monitoring dashboard. In our experience, none of those address what is actually happening. Incident response at enterprise scale has a structural problem, and it takes a structural solution.
The Gap That Generation 1 AIOps Did Not Close
The first generation of AIOps platforms brought real value. Tools like PagerDuty, BigPanda, Moogsoft, and Dynatrace absorbed noisy alert streams from dozens of monitoring tools, applied machine learning to correlate related events, and surfaced a cleaner, ranked incident feed for engineers to work from. That reduced a lot of manual signal-sorting and gave teams better situational awareness.
What those tools did not do is close the loop. They tell your team what broke. Everything that comes after, figuring out why it broke, locating the right runbook, traversing logs across Databricks, ServiceNow, GitHub, and your cloud console, applying a fix, and documenting the resolution, still falls entirely on a human engineer. The intelligence stops at the notification.
For teams managing hundreds of pipelines, that model has a ceiling. Your most experienced data engineers end up spending a significant portion of their week on incidents that are repetitive, well-understood, and genuinely resolvable without their level of expertise. That is the gap worth closing
Where the Market is Heading
The AIOps market is growing at around 30% annually and is projected to reach $41.6 billion by 2030. But the growth is not driven by better alert correlation. The momentum is in autonomous remediation: systems that can investigate an incident, identify the root cause, propose and execute a fix under human oversight, and close the ticket with a full audit trail.
Gartner projects that 40% of enterprise applications will include task-specific AI agents by the end of 2026, up from fewer than 5% in 2025. Snowflake's acquisition of Observe in January 2026 was a clear signal from the platform side: observability and incident response are becoming native to the data platform, not a separate tooling concern. The direction of travel is unambiguous.
What is changing is not just the ambition. Three specific developments have made production-grade autonomous incident response genuinely viable today in a way it was not a couple of years ago.
Durable Orchestration for Long-Running Agent Workflows
One of the practical obstacles with AI-driven remediation is that real incidents do not resolve in a single step. They involve multiple systems, run for minutes or hours, require state to persist across failures and retries, and need a human to review and approve any change before it reaches production.
Workflow orchestration engines address this directly. They provide durable, stateful execution: if the system fails mid-process, it resumes exactly where it left off. Human-in-the-loop checkpoints become first-class workflow features rather than workarounds. For teams building autonomous agent systems for production environments, the workflow engine has become one of the more important infrastructure choices, and it is worth understanding why.
Model Context Protocol as the Enterprise Integration Layer
Anthropic introduced Model Context Protocol (MCP) as an open standard in late 2024. Its practical value is that it gives AI agents a consistent, auditable interface to enterprise systems, whether that is ServiceNow, Databricks, Snowflake, GitHub, cloud environments, or Confluence. Before MCP, connecting an AI agent to enterprise tooling meant building and maintaining a custom integration for every system. MCP makes that modular.
For incident response specifically, this matters because every action an agent takes through an MCP connection is logged and governable. You can see exactly what the system accessed, what it read, and what it changed. A fintech team that implemented MCP-based incident response reduced MTTR from 45 minutes to under 5 minutes on their primary incident class. The integration layer is what makes that kind of speed possible while keeping the governance intact.
Multi-Agent Architecture: Specialist Agents Over Generalist Prompts
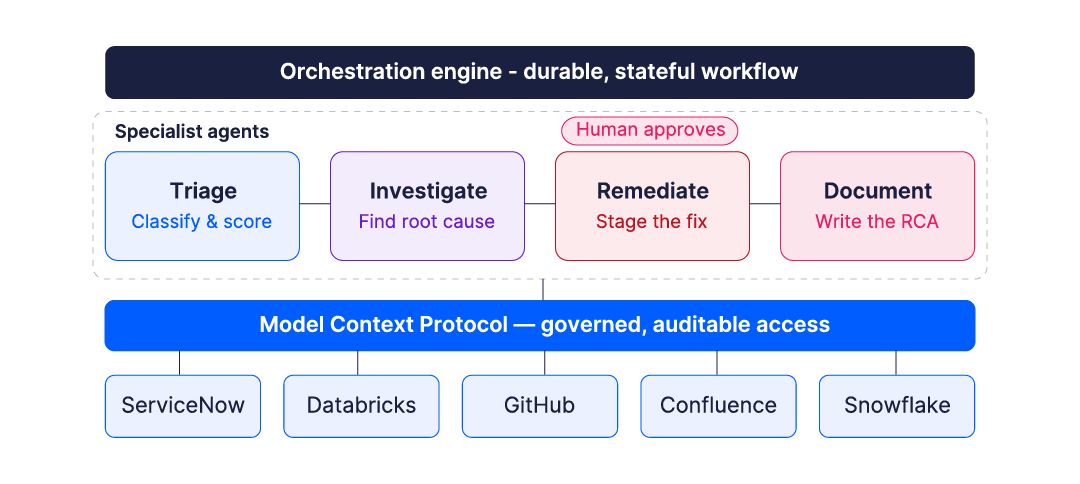
The temptation when working with large language models is to ask a single model to handle the entire workflow: read the ticket, investigate the logs, generate a fix, write the RCA. In practice, that collapses context, increases error risk, and makes the system difficult to audit.
The pattern that works better in production is to assign each part of the workflow to a specialist agent with a clearly defined scope. A triage agent classifies the incident and scores confidence. An investigation agent queries platform logs and cross-references documentation. A remediation agent proposes a fix and stages it for human review. A documentation agent writes the RCA back into the ticket. Each agent has defined tools, access policies, and cost guardrails. This is what translates an AI governance framework from a policy document into something that actually runs in a production system.
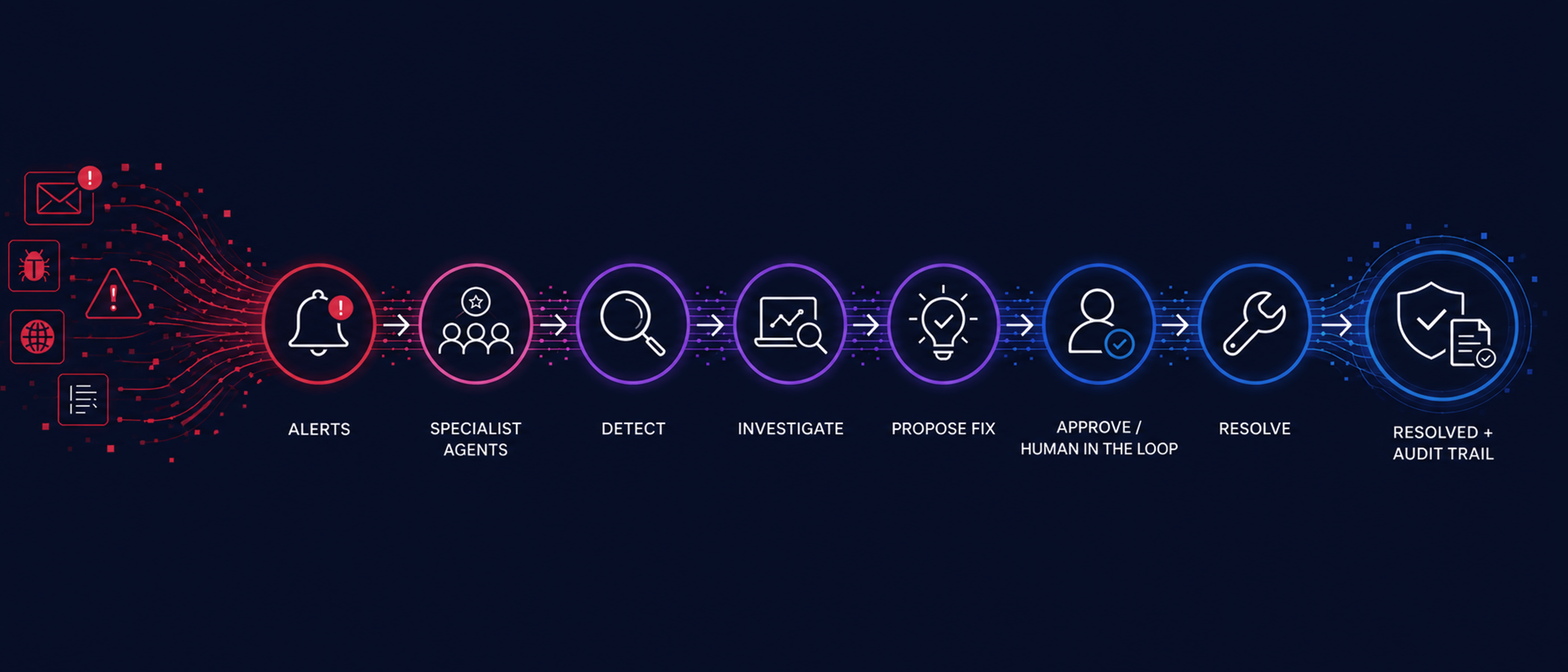
What the Workflow Actually Looks Like
Putting these components together, here is what a well-designed autonomous incident response system does when a data pipeline fails.
A ServiceNow ticket is created automatically when the job fails, or a message appears in a monitored Slack channel. This triggers the orchestration workflow without anyone needing to notice or act. The triage agent reads the incoming incident, classifies it, and assigns a confidence score. If the score is above a configured threshold, the investigation proceeds. Below that threshold, the ticket routes to a human reviewer.
The investigation agent connects to Databricks through MCP, pulls execution logs and job history, and retrieves relevant runbook documentation from Confluence. It reasons across those sources to generate a root cause hypothesis. If the cause is a code-level issue, it stages a pull request in GitHub with the proposed fix and waits for an engineer to review and approve. Once approved, the workflow resumes, the fix deploys, the pipeline reruns, and the ticket closes with a complete record of every decision, every action, and every system that was accessed.
For the highest-volume incident classes, the kind that consume significant time precisely because there are so many of them rather than because they are complex, this workflow completes in minutes. The engineer only enters the picture at the review step.
Governance Cannot Be an Afterthought
Any serious discussion about autonomous systems operating on production data infrastructure has to address governance directly. The concerns are legitimate: what happens when the agent makes the wrong call? Who is accountable? How do you know what the system did and why?
A well-designed autonomous incident response system answers these questions with architecture rather than assurances. Confidence thresholds determine when the system proceeds versus when it escalates to a human. PII and sensitive fields are redacted before they reach any LLM. Model selection is governed, with simpler models handling classification tasks and higher-reasoning models handling root cause analysis, and cost caps enforced per workflow. Every LLM call, system action, and decision is logged through the observability platforms , so you can answer any audit question about any resolved incident.
This is the audit capability that ITIL runbooks were supposed to provide but rarely did in practice. A runbook tells engineers what to do. An auditable autonomous workflow records what was actually done, by which component, with what justification, at what cost, and who signed off on the change.
Where to Start
The teams most immediately affected by this problem are those running Databricks or Snowflake pipelines at scale, where a pipeline failure has downstream consequences for reporting, inventory, financial reconciliation, or customer experience, and where the same engineering team supporting those pipelines is also responsible for building new capabilities.
The starting point does not require a mature knowledge base or a pre-existing runbook library. In our experience, the right entry point is identifying the highest-volume, lowest-complexity incident class in your current pipeline estate. That is usually the category of tickets that consumes the most engineering hours not because each one is hard but because there are so many of them. Design an autonomous workflow around that class first, keep the human approval gate in place until you trust the system, and expand from there as the knowledge base builds.
Organizations applying this approach to incident triage are seeing 25 to 40% reductions in mean time to resolution on their primary incident classes. At the scale of hundreds of pipelines across multiple cloud environments, that is a meaningful shift in how your team spends its time.
A Question Worth Asking Your Team
At GSPANN, we work with data engineering and DataOps teams at enterprises running complex pipeline estates on Databricks, Snowflake, and cloud-native infrastructure. The pattern we see consistently is that skilled engineers are spending their most productive hours on incidents that should not require their attention. That is what makes autonomous incident response worth thinking about seriously, not as a future investment but as something to evaluate now.
If this reflects what your team is dealing with, we would like to hear about it. What does your current incident volume look like? Where does the toil concentrate? What would it mean to your sprint velocity if your most common incident class handled itself? Those are the questions worth having before any solution is on the table.





