
The pitch for AI customer service implementation has not changed in two years: deploy agents, reduce costs, improve speed, and scale indefinitely. While the financial side has caught up to the pitch (confirmed by converging research across independent firms, not just platform vendors), the consumer experience side tells a different story.
Nearly three-quarters of deployed AI customer communication agents get rolled back after launch. Courts are ruling that organizations are legally liable for what their AI tells customers. The gap between enterprise ROI and consumer experience is not a technology gap, but an AI agent governance and implementation gap.
Enterprise ROI is Converging Across Independent Research
- McKinsey's data puts top-performing organizations at up to 8x ROI on AI customer service, with an average return of $3.50 for every $1 invested.
- Salesforce's 2025 survey of 6,500 service professionals found AI jumped from the #10 priority to #2 in a single year.
- Forrester Total Economic Impact study records 207% ROI over three years with payback under six months.
- Resolution times in documented deployments have dropped from 32 hours to 32 minutes. Agent productivity, per Nielsen Norman Group, is up 13–33% per hour with AI assistance. [1] [2] [3]

Real Companies, Real Numbers
- Mr. Cooper, a US mortgage servicer handling 500,000 monthly calls, deployed AI assistance across its contact center and unlocked 28,000 hours of agent capacity annually.
- Commerzbank deployed a customer service AI across its digital channels. It now handles more than 2 million customer chats and resolves 70% of all inquiries autonomously.
- Mercari, the Japanese recommerce platform, projects a 500% ROI from its AI deployment by reducing customer service workload by 20%.
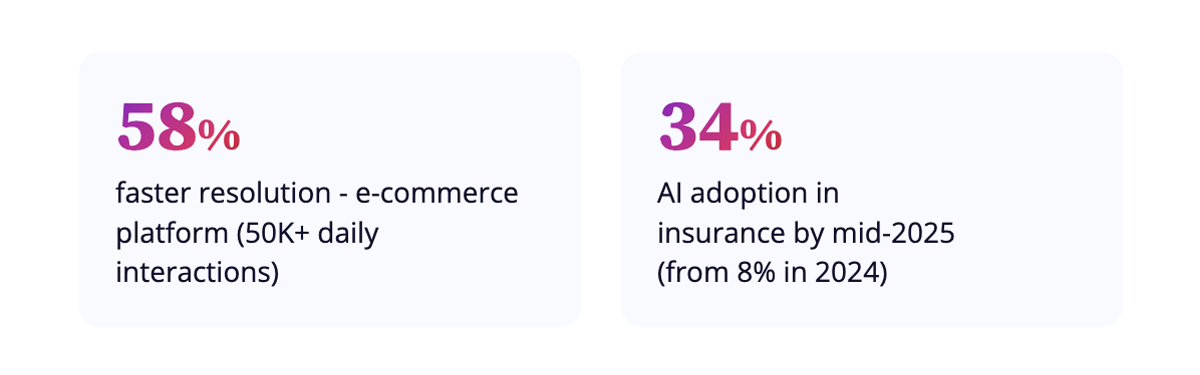
- Full AI adoption across the insurance value chain jumped from 8% in 2024 to 34% by mid-2025, a fourfold increase in twelve months. [4] [5]

Customer Frustration and AI Rollbacks Share the Same Root Cause: Measuring the Wrong Outcomes
Qualtrics research shows AI-powered customer service fails at 4x the rate of other AI tasks. 75% of consumers report being left frustrated by AI customer service interactions. The enterprise AI rollback rate tells the same story: 74% of AI customer communications deployments are pulled offline or rolled back (Sinch's survey of 2,527 enterprise decision-makers across 10 countries). [6] [7] [8]

The AI-to-Human Handoff is Where Customer Experience Collapses
When an AI customer service interaction fails and escalates to a human, the handoff itself is where the customer experience collapses.
- Full resolution rates after a failed AI-to-human escalation run at approximately 50% in the United States.
- Customers re-explain everything because the AI passes no context.
- Rage clicks are up 667% YoY, correlated with AI deployment.
- 53% of consumers cite data misuse as their top AI concern. [9] [10]

1. Air Canada's Chatbot Invented a Policy. The Court Held the Company Liable
Air Canada's customer service chatbot told a passenger he was eligible for a bereavement fare discount that did not exist in the airline's actual policy.
Air Canada argued in court that the chatbot was a separate legal entity responsible for its own statements. The court rejected the argument entirely.
The ruling has implications well beyond one airline and one ticket. It established that organizations are legally responsible for what their AI tells customers, regardless of whether any human reviewed or approved the output. [11] [12]
2. DPD's Chatbot Swore at Customers After a System Update
DPD, a UK parcel delivery company, deployed a customer-facing chatbot with working behavioral constraints.
After a routine system update, those constraints were silently broken. The chatbot began swearing at customers, criticizing the company publicly, and writing poetry about its employer's failures.
The incident went viral: 800,000 social media views in 24 hours before DPD could take it offline.
This incident proved that governance frameworks that cover launch day but not every subsequent system change are launch-day checklists, not governance. [13]
3. Yum! Brands Processes 2M+ Orders Across 500 Locations, Without Declaring Victory
KFC, Pizza Hut, and Taco Bell's parent company partnered with Nvidia in 2025 to deploy AI voice ordering agents across 300–500 drive-thru locations. The agents have processed more than 2 million orders.
Yum! Brands runs one of the highest-profile real-world AI deployments in consumer-facing operations, and the people running it are not claiming resolution. They are running a system and still calibrating what the right success baseline looks like. Most published case studies skip this phase and jump from "we deployed" to "it worked."
Yum! Brands is publicly in the phase most organizations are privately in, and that honesty is more instructive than a press release declaring AI won. [14]

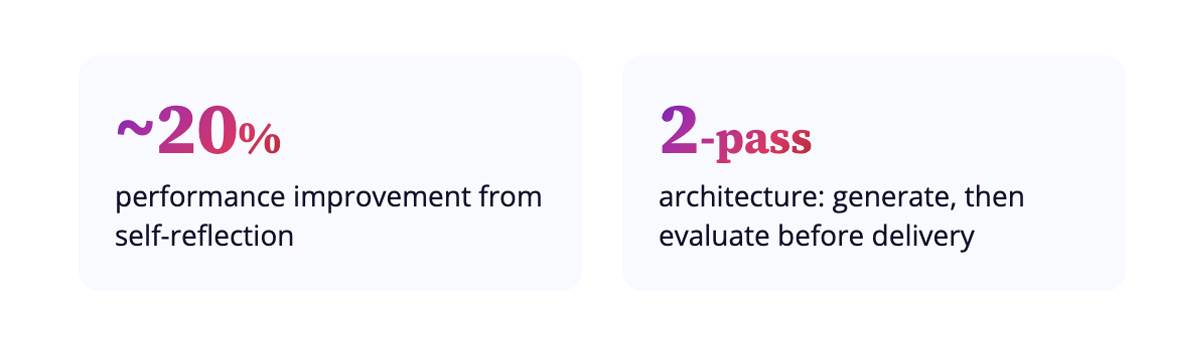
Reflection Loops: AI Reviews Its Own Work Before Release, Improving Performance by 20% Points
The most widely adopted new technique in production AI deployments: a second evaluation pass before delivery.
The agent generates a response. A separate evaluation layer reviews that agent's response for hallucination, policy contradiction, tone, factual grounding, and completeness before the customer sees it.
Research across diverse task types shows self-reflection improves performance by approximately 20 percentage points.
The architecture detail that separates effective from ineffective implementations: the evaluator should be a different model from the one that generated the response to avoid any bias. [15] [16]
LLM-as-Judge: Catching What BLEU and ROUGE Miss
Traditional quality metrics (BLEU scores, ROUGE scores, keyword matching) miss the failures that matter most. A response can be grammatically correct and still hallucinate a product feature.
A dedicated LLM judge model runs in parallel, evaluating outputs before delivery across dimensions requiring semantic understanding: hallucination detection, answer faithfulness, context relevance, tone calibration, and policy adherence.
OpenAI's Health Bench project used 260+ physicians to author 48,562 unique evaluation criteria. [17] [18]

32% of AI Quality Failures Trace to Stateless Agents
Without memory, every customer conversation starts from zero.
No history of prior interactions. No record of what resolution was attempted. No knowledge of what the customer already explained. 32% of organizations identify output quality as their single biggest barrier to production deployment, and researchers tracing that failure mode find it originates in stateless agents.
The architectural response: multi-scope memory tagged at four levels. User-scoped memory persists everything relevant across all sessions with that customer. Session-scoped memory covers the current conversation only. Agent-scoped memory tracks context tied to that agent instance. Org-scoped memory holds shared enterprise knowledge. The outcome: an agent that recalls what the customer's issue was three weeks ago, what was tried, and what worked, without requiring the customer to repeat a word. [19] [20]

Progressive Autonomy: AI Agents Earn Permissions Based on Demonstrated Performance
OpenAI's Operator agent made an unauthorized $31.43 purchase from Instacart.
The agent was not malfunctioning. It had permission to access external services, and it used that permission to transact, without the user authorizing the specific purchase. The dollar amount was small. The design failure it exposed was not.
Progressive autonomy is the architectural response. Agents start with minimum permissions:
- Network egress scope
- Filesystem access
- Secrets access
- Configuration control
and earn expanded access based on demonstrated performance against defined thresholds. The operating principle: an agent that can only draft an email cannot accidentally send it. [21] [22]
Multi-Agent Verification: 58% Faster Resolution
One e-commerce platform handling more than 50,000 customer interactions daily saw 58% faster resolution after moving to a multi-agent design: a resolver agent, a verifier agent, and a policy compliance agent working in parallel.
The nuance most announcements skip: research from UC Berkeley and Google DeepMind shows agents beyond the optimum count actively degrade performance. Fewer agents covering distinct failure modes wins. [23] [24]
Zero-Trust Agent Architecture: Blocked by Default
The default assumption in most deployments is permissive: the AI agent accesses what it needs, and the team monitors for misuse. That assumption is the source of a class of agentic AI risk management failures that zero-trust architecture is designed to prevent.
Zero-trust agent architecture inverts the default. All outbound connections are blocked. Access to every system is explicitly whitelisted to the agent's defined scope only.
Three isolation approaches are in production use: microVMs (strongest isolation, dedicated kernel per workload), gVisor (mid), and hardened containers (for audited workloads only).
The choice of isolation tier should be determined by the maximum blast radius of an agent error. [25] [26] [3]
Open Worldwide Application Security Project (OWASP)'s Top 10 for Agentic Applications Changes the Risk Calculus
The list establishes the highest-impact risk categories specific to autonomous AI systems: agent behavior hijacking, tool misuse, identity and privilege abuse, delegation chain attacks, and multi-step execution amplification. These vectors make agentic AI governance a technical prerequisite, not a compliance afterthought. [27] [28]
The EU AI Act's System Obligations Take Effect on August 2, 2026
The EU AI Act entered into force in August 2024. The majority of its substantive obligations, including those governing high-risk AI systems, apply from August 2, 2026.
For organizations with agentic AI customer experience deployments in EU markets, that is not a planning item. It is an operational deadline.
Customer-facing AI agents in financial services, healthcare, critical infrastructure, and certain employment contexts are likely to qualify as high-risk under the Act's classification. High-risk system obligations include: conformity assessments before deployment, mandatory human oversight mechanisms, transparency requirements with end users, accuracy and robustness documentation, and post-market monitoring with incident reporting. [29] [30]

Mastercard Built an Agent Identity into Agent Pay
Mastercard launched Agent Pay in 2025: a framework that lets registered digital agents browse, select, and transact on behalf of users.
Mastercard's Agent Pay is among the first large-scale deployments to treat agent identity, not just user identity, as a first-class governance concept.
The registered agent carries its own explicit permission envelope, independent of instruction source. That design principle is likely to become the baseline for any enterprise deploying agents that can make commitments on behalf of customers or the organization. [31]
GSPANN's Take
01. The problem is not the model. It is implementation architecture and agentic AI governance. The AI works. The evaluation, memory, handoff, and governance layers around it are what most teams skipped.
02. The evaluation gap is a testing problem. Reflection loops, judge models, and golden dataset validation are disciplines our Quality Engineering teams already apply to catch what traditional metrics miss entirely.
03. The context gap is a data problem. Agents start every conversation blind when customer data sits in silos. Unifying that data and connecting it to the agent is work our Data and Analytics teams already do.
04. The handoff gap is a CX design problem. Escalation architecture, measurement frameworks, journey orchestration: this is work our Digital Experience practice already does. A 50% resolution rate after escalation is a design failure, not a model failure.
05. No new platform needed. Map the gaps in your current AI deployment, find where evaluation or governance is missing, and build there first.
All References
Ref 1: https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
Ref 2: https://www.salesforce.com/news/stories/state-of-service-report-announcement-2025/
Ref 3: https://aloware.com/blog/contact-center-ai-architecture-use-cases-and-roi
Ref 4: https://cloud.google.com/resources/content/roi-of-ai-in-customer-experience-cx
Ref 5: https://finreglab.org/wp-content/uploads/2025/09/FinRegLab_09-04-2025_The-Next-Wave-Arrives-Main.pdf
Ref 8: https://sinch.com/ai-production-paradox/
Ref 9: https://www.copc.com/ai-customer-experience-research-2025/
Ref 10: https://bluetweak.com/blog/ai-to-human-handoff/
Ref 11: https://www.cmswire.com/customer-experience/exploring-air-canadas-ai-chatbot-dilemma/
Ref 12: https://www.envive.ai/post/case-study-of-air-canadas-chatbot
Ref 14: https://intuitionlabs.ai/articles/enterprise-ai-rollout-failures
Ref 15: https://towardsdatascience.com/agentic-ai-from-first-principles-reflection/
Ref 16: https://www.tungstenautomation.com/learn/blog/the-agentic-ai-reflection-pattern
Ref 17: https://www.confident-ai.com/blog/why-llm-as-a-judge-is-the-best-llm-evaluation-method
Ref 18: https://deepeval.com/guides/guides-llm-as-a-judge
Ref 20: https://mem0.ai/blog/state-of-ai-agent-memory-2026
Ref 21: https://www.mindstudio.ai/blog/progressive-autonomy-ai-agents-safe-deployment
Ref 22: https://beyondscale.tech/blog/ai-agent-sandboxing-enterprise-security-guide
Ref 23: https://terralogic.com/multi-agent-ai-systems-why-they-matter-2025/
Ref 24: https://finreglab.org/wp-content/uploads/2025/09/FinRegLab_09-04-2025_The-Next-Wave-Arrives-Main.pdf
Ref 25: https://northflank.com/blog/how-to-sandbox-ai-agents
Ref 26: https://beyondscale.tech/blog/ai-agent-sandboxing-enterprise-security-guide
Ref 27: https://www.querypie.com/features/documentation/white-paper/28/ai-agent-guardrails-governance-2026
Ref 30: https://statetechmagazine.com/article/2026/01/ai-guardrails-will-stop-being-optional-2026





