Spinnaker is an open-source, multi-cloud continuous delivery tool, originally designed and developed by Netflix. It helps in deploying the applications to various cloud providers like Google Cloud Platform (GCP), Amazon Web Services (AWS), and Microsoft Azure.
The purpose of this blog is to help the developers, architects, and business practitioners to understand the significance of using Spinnaker when adopting a Kubernetes environment. You will learn about:
- Role of Spinnaker in a Kubernetes environment
- Use of Spinnaker in a Kubernetes environment
- Understanding the Spinnaker architecture
- Using Spinnaker to design a continuous delivery pipeline
- Explaining the Spinnaker pipeline workflow
- Best practices of using Spinnaker to design a continuous delivery pipeline
Role of Spinnaker in a Kubernetes Environment
Various organizations adopt Kubernetes owing to its simplicity in managing a multi-container environment. However, Kubernetes is not a continuous delivery or deployment tool like Jenkins or Spinnaker. Earlier, the Kubernetes ecosystem lacked a simple continuous delivery tool to automatically build Kubernetes manifests, test those artifacts, and deploy those artifacts. Jenkins supports continuous delivery of applications on Kubernetes clusters, but with added complexity.
Spinnaker supports application deployment on Kubernetes clusters. It simplifies this process and helps the organization to deploy a production-grade build artifact on a Kubernetes cluster.
Spinnaker is also used to manage applications deployed on Kubernetes clusters with the help of its graphical user interface (GUI). Kubernetes manifest files can be edited and updated to provide the capability of editing Kubernetes-specific properties on the fly. With the help of Spinnaker GUI, you can also monitor Kubernetes object health status.
Use of Spinnaker in a Kubernetes Environment
Spinnaker is supported by various cloud providers, such as App Engine, Amazon Web Services (AWS), Azure, Google Cloud Platform (GCP), Cloud Foundry, Oracle, and Kubernetes. When you install Spinnaker with Kubernetes on the cloud, it provides Kubernetes native, manifest-based deployments. Spinnaker uses an account to authenticate against Kubernetes clusters.
Key functions of Spinnaker in a Kubernetes environment are application management and application deployment. The application management functionality helps in managing and viewing Kubernetes cluster objects. Various operations like scaling up, scaling down, rolling back, and rolling forward can be performed on Kubernetes objects using Spinnaker. This functionality of Spinnaker helps in managing multiple Kubernetes clusters from a single point of contact, i.e., Spinnaker GUI.
The application deployment functionality of Spinnaker is used to deploy various objects in a Kubernetes cluster. Spinnaker supports various kinds of deployment strategies while deploying applications in Kubernetes clusters, like Blue/Green, rolling updates, canary deployment, etc. To perform the application deployment, Spinnaker uses pipelines and stages. With the help of Spinnaker pipelines, you can create continuous delivery flows for automatically deploying code from a source code management tool to a Kubernetes cluster. You can also perform code validation before deploying anything on production Kubernetes clusters using Spinnaker stages.
Understanding the Spinnaker Architecture
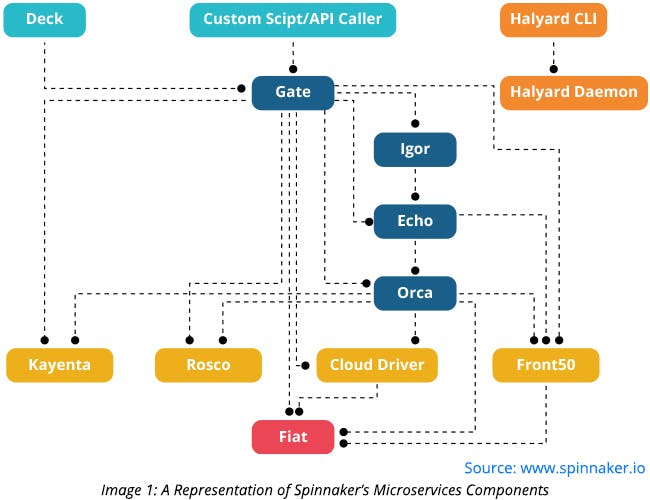
Spinnaker consists of independent microservices components. Some of these components are mentioned below:
- Deck: Provides a user interface to interact with the Spinnaker tool.
- Gate: Acts as an API gateway. It passes all API requests to the services.
- Orca: Handles various ad-hoc operations and manages pipelines along with its stages.
- Clouddriver: Makes calls to cloud providers. Acts as an integration point between the Spinnaker and cloud providers.
- Front50: Preserves metadata of applications, pipelines, and projects.
- Rosco: Bakes images that are later deployed on various cloud providers.
- Igor: Triggers pipelines through continuous integration platforms, like Jenkins and Travis CI.
- Echo: Sends notifications via emails, SMS, and Slack. It is also responsible for incoming webhooks, like Github webhooks and Jenkins webhooks.
- Fiat: Acts as an authorization service for Spinnaker.
- Kayenta: Provides automated canary analysis for Spinnaker.
- Halyard: A configuration service used for installing, updating, and configuring Spinnaker.
Using Spinnaker to Design a Continuous Delivery Pipeline
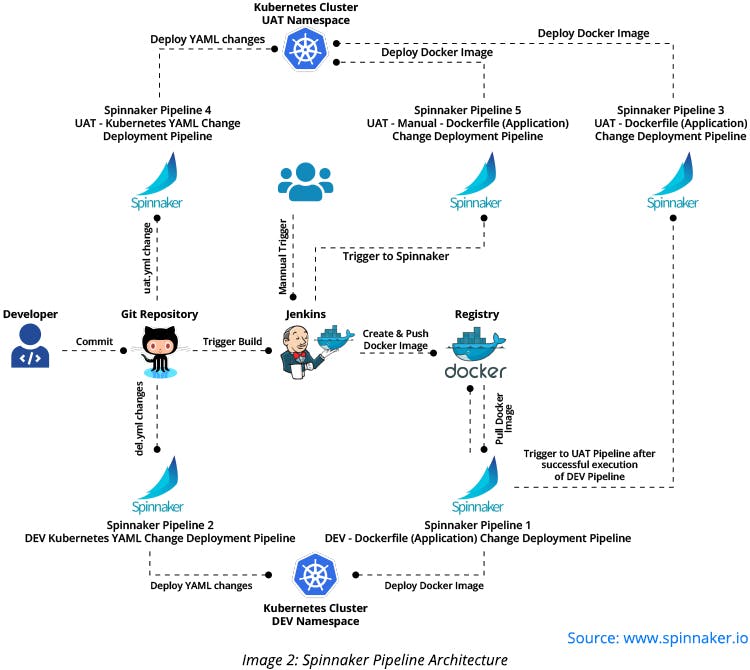
A continuous delivery pipeline is created to deploy Kubernetes manifest builds and application builds (docker images) on two different Kubernetes namespaces, namely DEV and UAT. To create a continuous delivery pipeline, you’d need a helm chart as a template for Kubernetes manifest files that are being used by Spinnaker to create final deployable Kubernetes manifest artifacts.
You can create five separate Spinnaker pipelines as mentioned below:
- DEV - YAML file change deployment for Kubernetes clusters: This pipeline is used to deploy Kubernetes manifest files change builds on DEV namespaces of Kubernetes clusters.
- UAT - YAML file change deployment for Kubernetes clusters: This pipeline is used to deploy Kubernetes manifest file change builds on UAT namespaces of Kubernetes clusters.
- DEV – Docker image - application deployment: This pipeline is used to deploy code changes as part of Docker images on DEV namespaces of Kubernetes clusters.
- UAT – Docker image - application deployment: This pipeline is used to deploy code changes as part of Docker images on UAT namespaces of Kubernetes clusters.
- UAT - Jenkins manual docker image deployment: This pipeline is used to manually deploy code changes as part of Docker images on UAT namespaces of Kubernetes clusters. It enables users to deploy the required application code (Docker image) manually on UAT namespace. The two Spinnaker pipelines mentioned above automatically deploy code on DEV and UAT namespaces respectively. It enables users to have control over their application code (Docker image) deployed on UAT namespaces.
Explaining the Spinnaker Pipeline Workflow
Kubernetes manifest files and application code (Docker image), that are scheduled to be deployed, should now be pushed to the GitHub repository.
- Webhook is configured on GitHub to automatically push change notifications to Jenkins, which is configured with jobs to automatically detect application code changes in GitHub.
- Jenkins jobs take the latest application code changes and build a Docker image. Using the Docker plugin, Jenkins pushes the newly created image with the corresponding tab to the Docker Hub registry where the application code is stored (Docker images).
- Corresponding Spinnaker pipelines continuously monitor the Docker Hub registry with the help of automatic triggers.
- After having the latest Docker image in the Docker Hub registry, you can execute Spinnaker pipeline triggers and deploy the corresponding application code (Docker image) on the DEV/UAT namespace of a Kubernetes cluster.
Let us discuss each pipeline in detail.
YAML File Change Deployment for Kubernetes Clusters Pipeline for DEV and UAT
This Spinnaker pipeline consists of four stages – Configure, Jenkins, Bake (manifest), and Deploy (manifest). The Configure stage is an automatic trigger configured to detect the changes in dev.yml/uat.yml files. If there is a change in these files, the execution of this pipeline will commence. The Jenkins stage sends a trigger to the Jenkins job, which executes a set of Linux commands on the existing Kubernetes cluster to detect the recently deployed Docker image tag. This stage ensures that the existing Docker image is not updated with the latest Docker image tag. Thereafter, Jenkins stage records the existing Docker image tag in a text file (for instance, build_uat_yml.properties).
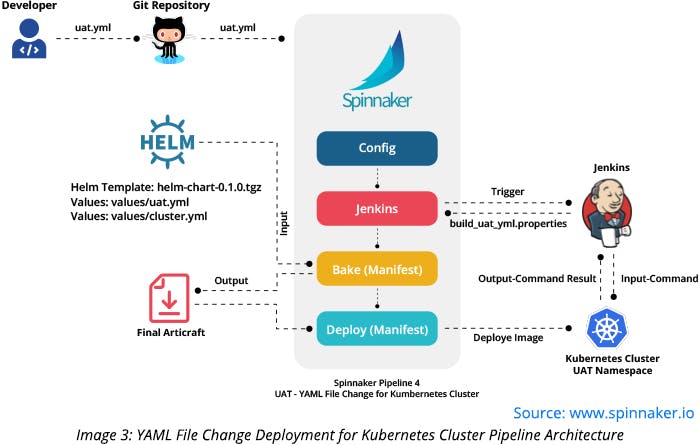
Later, the text file is passed to the next Spinnaker stage, i.e., Bake (Manifest). This stage is configured with a template containing variable for the image tag as “{{.Values.image.tag}}.” Spinnaker replaces this variable value with the key value present in build_uat_yml.properties/ build_dev_yml.properties file.
Spinnaker then creates a final build artifact containing Manifest values and the Docker image tag value recorded by a Jenkins job. Deploy (Manifest) stage uses this final artifact and deploys this Manifest build artifact on DEV/UAT namespaces without updating the existing Docker image tag.
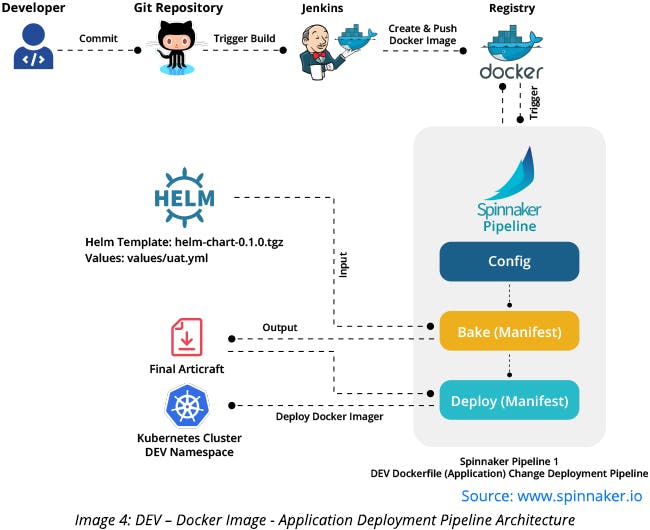
DEV – Docker Image - Application Deployment Pipeline
This Spinnaker pipeline consists of three stages: Configure, Bake (Manifest), and Deploy (Manifest). The Configure stage is configured with an automatic trigger to detect the newly pushed Docker images at the Docker Hub registry. Bake (Manifest) stage is used to create a Kubernetes manifest file from the existing helm chart template and defined dev.yml value file. The final artifact is created with the Docker image having the “latest” tag. Deploy (Manifest) stage uses the final artifact and deploys it in the DEV namespace of the configured Kubernetes cluster.
UAT – Docker Image - Application Deployment Pipeline
This pipeline uses the same flow as explained above to create the final artifact from the existing helm chart template and a defined uat.yml value file. The only difference here is that, in this stage, an automatic trigger is configured as the execution result of the ‘DEV – Docker image - application deployment’ pipeline. The successful execution/completion of the ‘DEV – Docker image - application deployment’ pipeline will commence the execution of the pipeline. If the execution of ‘DEV – Docker image - application deployment’ pipeline enters a failed state, the execution of this pipeline will never commence, which will prevent the deployment of failed artifact build in the UAT namespace of a Kubernetes cluster.
UAT - Jenkins Manual Docker Image Deployment Pipeline
This pipeline helps the users to deploy old Docker image artifact in UAT namespaces as per their requirement. The users provide the required Docker image tag to be deployed through a parameterized Jenkins job that creates a text file (for instance, build.properties) with user-provided Docker image build as content. For example – IMAGE_TAG=v15. Here, v15 is the image tag provided by a user.
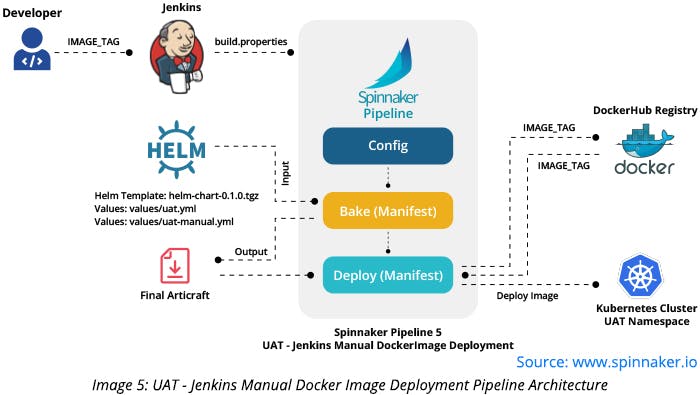
The build.properties file is passed as an input to the Spinnaker pipeline. Bake (Manifest) stage is configured with a template containing variable for the image tag as “{{.Values.image.tag}}.” Spinnaker replaces this variable value with the key value present in the build—properties file. Spinnaker then creates a final build artifact containing Manifest values and a Docker image tag value passed by the user. Deploy (Manifest) stage uses this final artifact and deploys this Manifest build artifact on a UAT namespace by pulling the corresponding Docker image with the mentioned tag.
Best Practices of Using Spinnaker to Design a Continuous Delivery Pipeline
- Spinnaker provides GUI that allows the users to perform application management, like directly editing Kubernetes object YAML definition files through GUI. But most of the time, source code management tools are used to store and version Kubernetes object YAML definition files. In such a scenario, any YAML file changes done through Spinnaker GUI will be overwritten during the next Pipeline deployment. Thus, it is highly recommended to make changes in YAML files stored in source-code management tools instead of editing YAML files directly through the Spinnaker GUI.
- Configure the Spinnaker pipeline trigger with Docker image push instead of GitHub push trigger or Jenkins job trigger. This practice avoids restructuring of the build and validation system.
- Do not bake Secrets inside the Docker images. Secrets should be loaded during the runtime using the cloud provider’s key management service.
- Use audit logs to determine which operation has been performed, when was it performed, and who performed it. It is a best practice to generate audit logs for Spinnaker by integrating it with cloud monitoring services, like GCP Stackdriver and AWS CloudWatch.
- Deploy Docker images on Kubernetes clusters through Kubernetes object YAML files. There are two ways of defining Docker images in YAML files, i.e., by defining image tags or defining image digest. The best practice is to define Docker images in YAML files by their digest. This approach would ensure that the deployed Docker image will always point to the same content.
Spinnaker is a robust continuous delivery tool used to automate the deployment of applications on Kubernetes clusters. Spinnaker pipelines can also be configured to perform unit tests and functional tests on build artifacts before performing the actual deployments. Thus, Spinnaker can help organizations to get code to the production environment faster.

Tushar Patil
Technical Lead – DevOps
Published Aug 18 2020



