
In this modern era, data has become a game-changer. It helps organizations make critical and informed business decisions, especially as teams weigh delta lake vs data lake choices for storage and governance.
While many companies collect data through various sources, the most challenging part, the differentiator, is to store and manage the data effectively. Given that the escalating volume of data is becoming increasingly challenging to handle, there is a notable shift from traditional databases towards more contemporary architectural layers, including cloud-based solutions, data lakes, and delta lakes.
What is Databricks: Executive Summary
What is Databricks? Databricks is a unified, open analytics platform designed for enterprises to build, deploy, share, and maintain enterprise-grade data, analytics, and AI solutions at scale. As a cloud-based data processing and analysis platform, Databricks enables organizations to easily work with large amounts of data while simplifying critical workflows such as ETL (Extract, Transform, Load) and data warehousing. The platform offers a data-centric approach to building better AI solutions, consolidating data management, analytics, and machine learning capabilities into a single integrated environment. By providing a unified workspace for data engineers, data scientists, and analysts, Databricks, paired with data engineering services, reduces complexity and accelerates time-to-value for enterprise data and AI initiatives.
What is Delta Lake in Databricks?
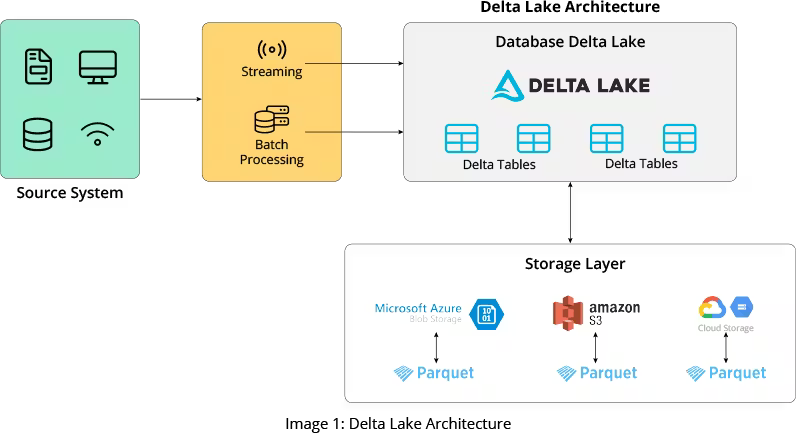
Delta Lake is an open-source storage framework that stores data and tables in Parquet files. Delta Lake is compatible with Apache Spark, which supports batch and stream data processing. Azure Databricks uses Delta Lake as its default storage and refers to its tables as Delta tables.
The underlying storage layer for Databricks Delta Lake can be AWS S3, GCP GCS, or Azure BLOB. This article discusses Databricks Delta Lake implementation in Azure and shares best practices to optimize the reads and writes in Delta Lake for better efficiency.
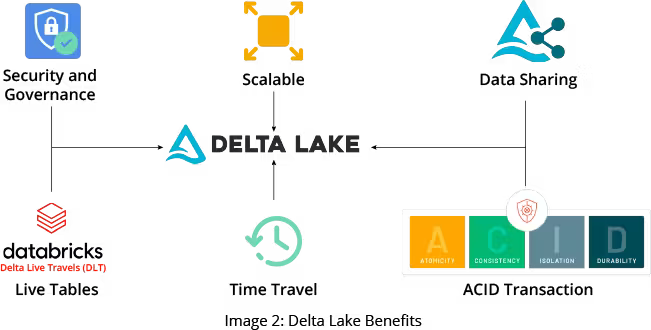
Benefits of Using Delta Lake
The Databricks Delta Lake implementation has many benefits. It is built on a hybrid model that embraces data warehousing and Spark multi-processing principles.
A typical implementation would provide support for:
- ACID transactions: Delta Lake supports ACID transactions (Atomicity, Consistency, Isolation, and Durability), which provides consistent data and transactional integrity.
- Scalable: All metadata operations in Delta Lake use an Apache Spark compute engine where data is scalable. This ensures Delta Lake can handle enormous amounts of data without a performance bottleneck.
- Security and Governance: Delta Lake provides secure and reliable storage of data, which has fine-grained access control for all underlying data at various levels viz, table, row, and column. Security is easy to implement and protects sensitive data from unauthorized access.
- Time Travel: Imagine if your business suffered from data corruption or incorrect data updated to a sizeable transactional table. In a traditional database, restoring integrity can cost a substantial amount of time and money. However, Delta Lake provides a version history feature that helps prevent data corruption. The table data can roll back to previous versions by running a simple command in Databricks Notebook.
- Data Sharing: Delta tables can be easily and securely shared with other users. It is platform-independent and supports recipients from outside your organization as well.
- Live Tables: You can use the Delta Lake Live Tables feature to build reliable and sustainable data processing pipelines. Live Tables provides an end-to-end solution for your ETL (Extract, Transfer, Load) pipeline. This feature supports data selection, transformation, quality control, automated testing, and monitoring.
For many people, the difference between “Delta Lake” and “Data Lake” is not very clear. Our blog, “Delta Lake vs. Data Lake - Which One Provides High-Quality Data You Can Trust?”.
Implementing Delta Lake
The strength of Delta Lake lies in its compatibility with various programming languages, like Spark SQL, Scala, and Python. To get started, it requires specific prerequisite libraries to be installed, depending on the programmer’s preference. Once these libraries are in place, the process becomes quite straightforward. It makes establishing a Delta table as easy as executing a Data Definition Language (DDL) statement, just like any relational database.
Click here to explore more on implementing Delta Lake.
Here’s a skeleton statement to create a Delta table:
CREATE TABLE delta. <delta-table-name>
<columns, datatype>
USING DELTA OPTIONS
(path <Azure blob storage path>)
Databricks Delta tables support common Data Manipulation Language (DML) operations such as SELECT, INSERT, UPDATE, DELETE, and UPSERT, which you can write in SQL, Python, Scala, and Java.
Delta Lake processing is powered by a Databricks compute engine, which is part of a Databricks cluster. The cluster needs to be up and running to read or write data from the Delta Lake tables. You can use the same cluster to run any Python, Scala, or SQL commands in the Databricks notebooks.
Optimizing and Implementing Best Practices in Delta Lake
Delta Lake is a great solution for storing and managing data. However, following the right methodology is crucial to avoid bad database design and performance bottlenecks.
Here are some best practices you can follow while designing Delta Lake tables:
| Practice | Description |
|---|---|
Right Partition Column | When designing a Delta Lake table, selecting the appropriate column partition is crucial to enhance its read performance. Avoid using high cardinality columns, like "transactionId" in a sales table or "orderId" in an order table, as your partition choice. Instead, consider using columns like Year, Month, or Date for partitioning. |
Compact Files | When a table experiences regular write operations in small batches, it can gradually accumulate a large number of files within the storage layer. It's recommended to streamline Delta Lake tables periodically by executing the "OPTIMIZE" command. |
Overwrite Instead of Delete | Delta Lake's overwrite operations are significantly quicker than its delete functions. These operations are atomic, guaranteeing that previous table versions remain accessible through the Time Travel feature. Avoid accessing the storage layer directly and deleting the underlying files. |
Z-Order for Large Tables | If a table contains a vast dataset and features a column often used in query predicates with high cardinality, applying Z-Order to the data can substantially enhance read performance. Columns like "transactionId," "orderId," or "userId" are excellent examples. |
Conclusion
You now know what performance optimization techniques to apply when building a Delta Lake table. However, remember that these optimizations need a Databricks compute engine, which can incur high costs. You should choose what works best for your organizational needs and determine the best trade-off between performance and cost. Databricks Delta Lake is an excellent tool for small to large enterprises’ data needs and is one of the most popular and reliable big data solutions.





