
Data lakes are becoming increasingly popular tools for data-driven organizations. They offer an easy way to store, manage, and process massive volumes of data, giving businesses access to powerful insights. But, with so much data to manage, how can you be sure that the data you are collecting is of high quality?
That’s where Delta Lake comes in. Databricks Delta Lake is a powerful technology that enables businesses to ensure that their data is accurate and reliable, allowing them to make informed decisions backed by accurate data. It is an open-source storage layer that brings ACID (Atomic, Consistent, Isolated, Durable) compliance to Apache Spark and big data workloads. Companies spend millions of dollars getting data into data lakes. Data engineers use Apache Spark to perform Machine Learning and build recommendation engines, fraud detection, IoT, and predictive maintenance, among other uses. But the fact is that many of these projects fail to get reliable data.
Switching from a traditional data lake to Delta Lake gives you the tools to produce a scalable analytics implementation. The steady stream of high-quality data allows business units to ‘see further’, and to make accurate business decisions, improving company profitability.
Traditional Data Lake Challenges
Traditional data lake platforms often face these three challenges:
- Failed production jobs: Failed production jobs leave data in a corrupted state and require data engineers to spend tedious hours defining jobs to recover the data. Ultimately, it's often necessary to design scripts to clean up and revert transactions in such situations.
- Lack of schema enforcement: Most data lake platforms lack a schema enforcement mechanism. The lack of this ability often leads to the production of inconsistent and low-quality data.
- Lack of consistency: When you read data while a concurrent write is in progress, the result will be inconsistent until Parquet is fully updated. When multiple writes are happening in a streaming job, the downstream apps reading this data will be unreliable because of no isolation between each write.
Why Use Delta Lake?
The traditional approach to data lakes often involves storing large amounts of raw data in Hadoop Distributed File System (HDFS), with limited options to run transactions and other forms of analytics.
This limits the scalability of your analytics implementation and can be a costly process. However, Databricks Delta Lake is an open-source storage layer that enables you to bring ACID transactions to Apache Spark and big data workloads. By using Delta Lake, you can ensure that your analytics implementation is scalable, reliable, and consistent.
Delta Lake is also compatible with MLflow. Earlier, Delta Lake was available in Azure and AWS Databricks only. In this earlier incarnation, Delta Lake data was stored on DBFS (Databricks File System) which might sit on top of ADLS (Azure Data Lakes Storage) or Amazon S3. Delta Lake can now be layered on top of HDFS, ADLS, S3, or a local file system.
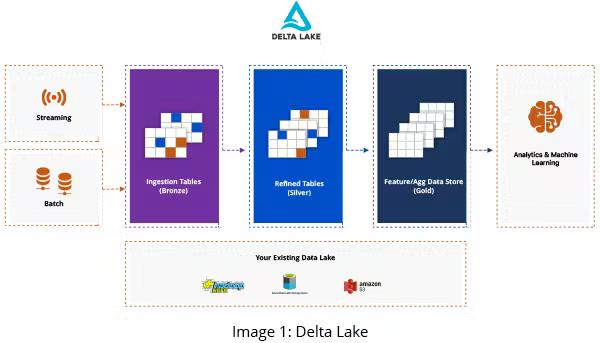
Delta Lake Features
Delta Lake provides a transactional storage layer that sits on top of existing data lakes and leverages the capabilities of Apache Spark to offer strong reliability and performance. When switching from a traditional data lake to Delta Lake, you can improve your analytics implementation with the following features.
- transaction support
- unified batch and stream processing
- schema enforcement
- time travel or versioning
These features make Delta Lake an ideal solution for improving the scalability, reliability, and consistency of your analytics implementation. With Delta Lake, you can ensure that your analytics processes are secure, consistent, and accurate. Let's first look at transaction support
ACID Transactions on Spark
Delta Lake supports ACID transactions, meaning it ensures data integrity and consistency by allowing multiple users to read and write to the same table simultaneously. This feature ensures that no data is lost or corrupted during analytics processes.
Typically, many users accessing a data lake cause data reads and writes to occur continuously throughout the day. It is vital to maintain data integrity at all times.
Transaction support based upon ACID is a key feature in most local databases. Yet, when it comes to HDFS or S3, it is tough to give the same durability guarantees as provided by ACID-compliant databases.
Delta Lake stores a transaction log to keep track of all commits made to the table directory, making it possible for Delta Lake to provide full ACID transaction support. The log offers serializable isolation levels that ensure data consistency among multiple users.
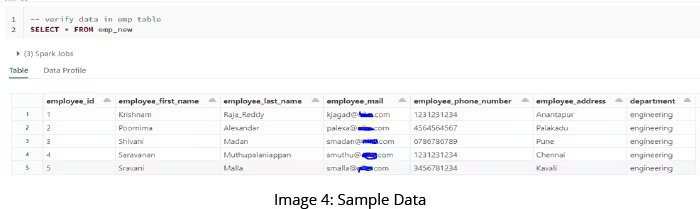
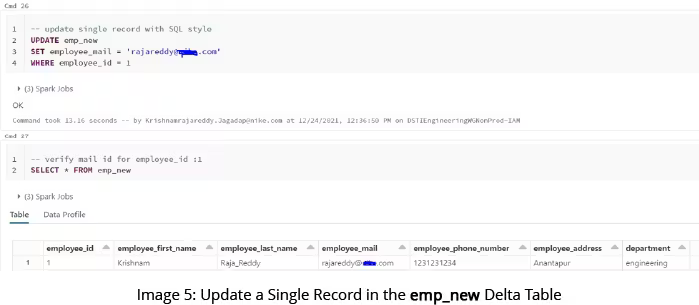
As you can see from images 2 to 5, creating and manipulating a Delta Lake table has many similarities to relational database systems.


Unified Batch and Stream Processing
In data lake, it is customary to use Lambda architecture if you need both Stream processing and Batch processing. On the other hand, in Delta Lake, data coming in as a stream or existing historical data can both use the same table.
For example, streaming data might originate from Kafka, and batch data might come from HDFS or S3. Delta Lake gives you a unified view from both sources. Streaming data ingest, batch historic backfill, and interactive queries work well out of the box without extra effort.
Schema Enforcement
Delta Lake prevents bad data from contaminating your data lakes by allowing you to specify the schema and enforce it. An enforced schema avoids data corruption and the mechanism prevents bad data from entering the lake even before data ingestion. This process also provides timely and sensible error messages.
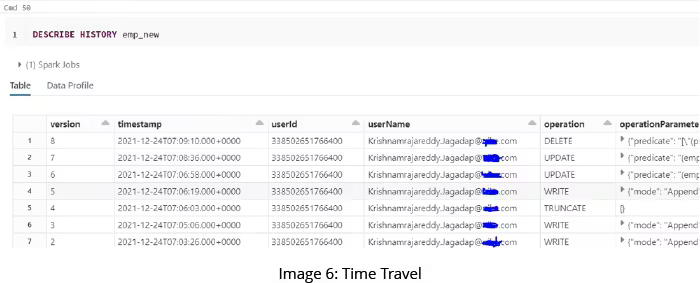
Time Travel or Versioning
Time Travel allows you to access previous versions of your data so that you can easily analyze the differences between versions. Data in Delta Lake is versioned and snapshots are available for you to query. A snapshot is treated as if it is the current state of the system. This helps in reverting to older versions of your data lake for audits, and rollbacks, among other possibilities. This makes it easy to audit data quality and ensure accuracy over time.
How Does Delta Lake Work?
Delta Lake is based on Apache Parquet, an open-source column-oriented data format. Delta Lake adds transactional awareness to Parquet using its transaction log, which is maintained in a separate folder named _delta_log under the table directory. Many vendors, such as Informatica and Talend, embrace Delta Lake in conjunction with their work on native readers and writers.
JSON files in the _delta_log folder will have information that could include any of the following:
- Type of Information — Usage
- Add or remove Parquet files — Maintains atomicity
- Stats — Helps with performance optimization and data skipping
- partitionBy — Partition pruning
- readVersions — Time travel
- commitInfo — Auditing
Image 7 shows a list of JSON files present in the Delta transactional log. Notice that it analyzes the status like metadata, add, minimum, and maximum in each file, which skips unnecessary data and optimizes performance.

- What is the Transaction Log?
- The transaction log is a folder with flat JSON files. It contains transaction information that provides Spark readers and writers with awareness of ongoing transactions. This gives Spark the ability to perform atomic transactions automatically.
How Changing Data Capture Leverages Delta Lake
Timely insights have become the norm in modern business. Business units effectively leverage their valuable data to derive high-probability outcomes. Such deep insights help them to make value-focused business decisions.
Thus, to pull data from the database without unduly impacting database performance, you need a tool to read and translate database's transaction logs. There are many tools, like Attunity, Debezium, IBM InfoSphere Change Data Capture (CDC), etc., that help in reading transaction logs and converting them into usable messages.
While running the MERGE command, those files are rewritten in case of any updates or deletions. Also, old files are marked for REMOVE and new files are kept under ADD in transaction log files. Based on this, businesses can consume the latest snapshot data from Delta Lake, which was otherwise a cumbersome job to implement the equivalent of a snapshot in data lake.

If a file is deleted manually from your file system, transaction logs are unable to capture it. Hence, it is highly recommended that you perform all the actions with utilities included in the Delta Lake platform. Otherwise, you will get inconsistent results when retrieving data from Spark Data Frame reader.
Conclusion
Delta Lake holds more significant functionality than a traditional data lake. The enhanced functionality includes data versioning as well as conditional updates and deletes. Delta Lake also supports "upserts," whereby existing entries are updated, and if the entry does not exist, it is inserted.
The bottom line is that switching to Delta Lake makes excellent business sense. By implementing Delta Lake, your business units will receive high-quality data to make business projections further out into the future based on accurate data. This functionality will give your business a massive competitive advantage.





