SAP HANA is one of the fastest-growing products in SAP’s 49-year-old history. It is an in-memory database engine that can analyze large datasets in real-time. Companies conduct various performance optimization techniques for SAP HANA to streamline and automate the data management process.
This blog highlights various SAP HANA performance tuning techniques in the following segments:
- SAP HANA Table-level Optimization
- Optimization of SAP HANA Stored Procedures / Scripted Calculation Views / Table Functions
- Leveraging SAP HANA Using Linked Server
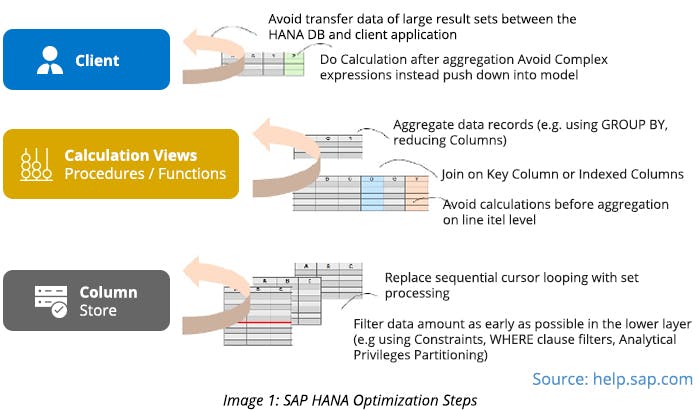
SAP HANA Table-level Optimization
You can improve the performance of any SAP HANA system following the best practices mentioned below:
- Use the appropriate table type based on the usage. If a table is small and almost all columns of the table are used in most of the queries, then use the Row-type table. For all other cases, use a Column-type table.
- Avoid using indexes on non-unique columns. Since every index imposes an overhead in terms of memory and performance, it’s better to create as few indexes as possible. Also, use fewer columns in an index.
- Get better performance by assigning range, hash, and round-robin partitions to the large tables since the amount of data brought into working memory can be limited.
Optimization Techniques for SAP HANA Stored Procedures / Scripted Calculation Views / Table Functions
The SAP HANA optimization is necessary to avoid the termination of tasks or processes when they breach the memory threshold (set for each process). It also improves resource utilization, such as memory and CPU time required.
Based on our experience, you can tune your stored procedures by following the best practices mentioned below:
- Use input parameters to filter the required data at the source level.
- Replace local temporary tables with table variables. Unload the tables as soon as they are not required for further processing when using large tables.
- Reduce the overall memory consumption by partitioning large tables, which brings lesser data into working memory. The type of partitioning and columns used for partition should be determined based on the ways the table is used in a majority of scenarios.
- Instead of writing complex queries, it is recommended to split a complex query into multiple simple queries for better optimization.
- In case of delta processing on tables that don’t have a timestamp, create a table that stores the key, timestamp (of the record coming into the HANA system), and populate this table by using triggers. While processing, extract records from the main table about a period of time by joining with the delta table.
- If a process requires a large amount of data to be processed quickly (and you have exhausted all other options), then materialize the slow-changing data and store the partial results in a separate table. Schedule this materialization process to run at appropriate intervals to refresh its data. Once you have the data in a materialized table, then you can use this table and decrease the number of tables used in the main stored procedure.
- Using query pruning technique by using input parameters, i.e., when a user specifies the data/table that is required at that moment via input parameters, you can prune the logic that is not needed to fetch the requested data.
- Use table functions instead of scripted calculation views.
-
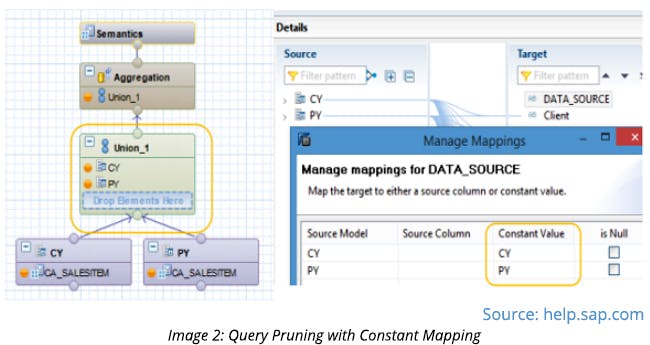
In graphical calculation views, that bring a large volume of data, use query pruning to minimize data load based on users’ selection.
-
In a calculation view, minimize the amount of data that will be pulled into the working memory by using input parameters and applying filters at source projection in the data flow. If the calculation view is a union of multiple calculation views, then constant mapping in the union node will result in performance improvement by using query pruning, where the data is pulled only from the desired subview (See the picture below).
While the above-mentioned optimization techniques can help you with SAP HANA optimization, there are some things that you must avoid in the process:
- Using Smart Data Access (SDA) – SDAs use a high-level of memory consumption
- Using cursors
- Data conversions - since creating columns to be converted in every query for the desired data type is expensive
- Using calculated columns in ‘joins’
- Aggregation nodes
- Apply IS NULL check before filtering the data - filter the data set before applying the IS NULL check because they prove to be expensive on large data sets
Leveraging SAP HANA using a Linked Server
For a large number of stored procedures that are already present in a different environment, like SQLServer or Oracle, instead of migrating the stored procedures to SAP HANA, leverage the power of HANA by creating a linked server connection between the existing system and SAP HANA. This will reduce the overall effort and cost of development.
Benefits of using a linked server:
- Reduced cost and effort required to migrate logic to HANA
- Doesn’t require migration of non-SAP tables to HANA
- Leverage the power of SAP HANA by pushing most of the logic that involves SAP ERP Central Component (ECC) tables to HANA
Here are a few examples of OpenQuery to fetch the data from HANA:

Dharanidhar Malluri
Sr. Technical Lead
Published Oct 13 2020





